容器
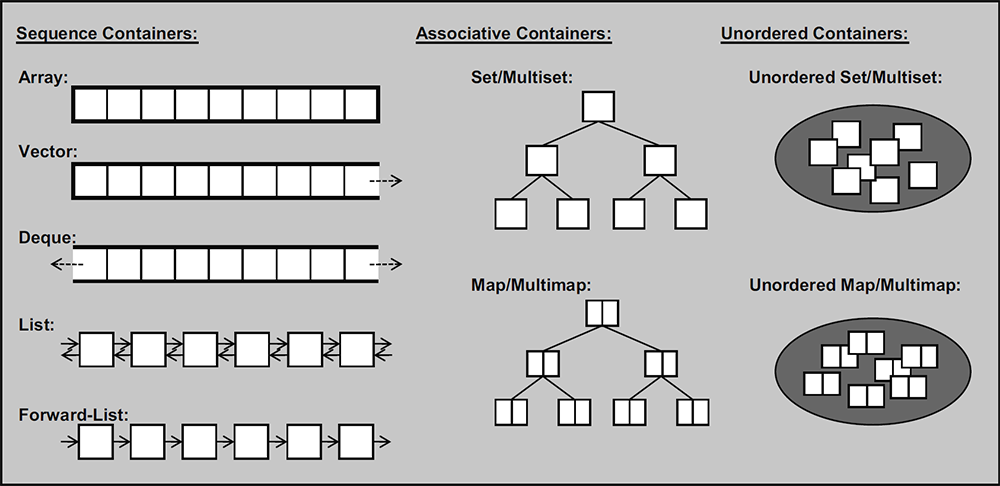
大多数计算任务都会涉及到创建值的集合然后对这些集合进行操作. 一个简单的例子就是读取字符存入string当中,然后打印这个string. 如果一个类的主要目的是保存对象, 我们通常称之为容器. 对给定的任务提供合适的容器即其上有用的基本操作,是构建任何程序的重要步骤.
容器用于表示由同类型元素构成的、长度可变的元素序列。
容器是由类模板来实现的,模板的参数是容器中元素的类型。
STL中包含了很多种容器,虽然这些容器提供了一些相同的操作,但由于它们采用了不同的内部实现方法,因此,不同的容器往往适合于不同的应用场合。
-
顺序序列 顺序容器中的元素按照严格的线性顺序排序。可以通过元素在序列中的位置访问对应的元素。
-
动态数组 支持对序列中的任意元素进行快速直接访问,甚至可以通过指针算述进行该操作。提供了在序列末尾相对快速地添加/删除元素的操作。
-
能够感知内存分配器的(Allocator-aware) 容器使用一个内存分配器对象来动态地处理它的存储需求。
-
序列式容器
- 向量(vector) 后端可高效增加元素的顺序表。
- 数组(array)C++11,定长的顺序表,C 风格数组的简单包装。
- 双端队列(deque) 双端都可高效增加元素的顺序表。
- 列表(list) 可以沿双向遍历的链表。
- 单向列表(forward_list) 只能沿一个方向遍历的链表。
-
关联式容器
- 集合(set) 用以有序地存储 互异 元素的容器。其实现是由节点组成的红黑树,每个节点都包含着一个元素,节点之间以某种比较元素大小的谓词进行排列。
- 多重集合(multiset) 用以有序地存储元素的容器。允许存在相等的元素。
- 映射(map) 由 {键,值} 对组成的集合,以某种比较键大小关系的谓词进行排列。
- 多重映射(multimap) 由 {键,值} 对组成的多重集合,亦即允许键有相等情况的映射。
-
无序(关联式)容器
- 无序(多重)集合(unordered_set/unordered_multiset)C++11,与 set/multiset 的区别在于元素无序,只关心「元素是否存在」,使用哈希实现。
- 无序(多重)映射(unordered_map/unordered_multimap)C++11,与 map/multimap 的区别在于键 (key) 无序,只关心 "键与值的对应关系",使用哈希实现。
-
容器适配器
- stack
- queue
- 优先队��列 std::priority_queue 是一种 堆,一般为 二叉堆。
谓词就是返回值为真或者假的函数。STL 容器中经常会使用到谓词,用于模板参数。
容器适配器
容器适配器是一个封装了序列容器的类模板,它在一般序列容器的基础上提供了一些不同的功能。之所以称作适配器类,是因为它可以通过适配容器现有的接口来提供不同的功能。比如stack<T>容器适配器
容器适配器其实并不是容器。它们不具有容器的某些特点(如:有迭代器、有 clear() 函数……)。
适配器是使一种事物的行为类似于另外一种事物行为的一种机制,适配器对容器进行包装,使其表现出另外一种行为。
栈(stack) 后进先出 (LIFO) 的容器,默认是对双端队列(deque)的包装。 队列(queue) 先进先出 (FIFO) 的容器,默认是对双端队列(deque)的包装。 优先队列(priority_queue) 元素的次序是由作用于所存储的值对上的某种谓词决定的的一种队列,默认是对向量(vector)的包装。
概述
| type | descriptions |
|---|---|
| vector<T> | 可变大小向量 |
| list<T> | 双向链表 |
| forward_list<T> | 单向链表 |
| deque<T> | 双端队列 |
| set<T> | 集合(只有关键字没有值的map) |
| multiset<T> | 允许重复值的集合 |
| map<K,V> | 关联数组 |
| multimap<K,V> | 允许重复关键字的map |
| unordered_map<K,V> | 采用哈希搜索的map |
| unordered_multimap<K,V> | 采用哈希搜索的multimap |
| unordered_set<K,V> | 采用哈希搜索的set |
| unordered_multiset<K,V> | 采用哈希搜索的multiset |
| queue<T> | |
| stack<T> | |
| priority_queue<T> | |
| array<T,N> | 定长数组 |
| bitset<N> |
我们知道,unordered_set和unordered_map与set和map是一样的,前者不是真正的键值对,它的value值和key值相同;后者是真正的键值对。STL非常注重代码的复用,它们在底层使用了同一棵红黑树模板实现,这也是此文要用同一个哈希表实现unordered_set和unordered_map的原因。如果各自拥有一个哈希表,set和unordered_set只要一个key值即可。
unordered_set
template<class K>
class unordered_set
{
public:
// ..
private:
HashTable<K, K> _ht;
};
unordered_map
template<class K, class V>
class unordered_map
{
public:
//...
private:
HashTable<K, pair<K, V>> _ht;
};
标准库容器的部分操作
| operates | descriptions |
|---|---|
| p = c.begin() | p指向c的首元素, c.begin()返回指向const的迭代器 |
| p = c.end() | p指向c的尾后位置, c.end()返回指向const的迭代器 |
| k = c.size() | k是c元素的数目 |
| c.empty() | 空返回true |
| k = c.capacity() | c能容纳的元素数目 |
| c.reserve(k) | 令c容量变为k |
| c.resize(k) | 令c的元素数目变为k, 如需要添加值为value_type的元素 |
| c[k] | c的第k个元素,无范围检查 |
| c.at(k) | c的第k个元素,越界out_of_range异常 |
| c.push_back(x) | c后添加x,大小+1 |
| c.emplace_back(a) | 将valuetype {a}添加到c的末尾,将c的大小增加1 |
| q = c.insert(p,x) | 将x添加到p之前 |
| q = c.erase(p) | 删除p处的元素 |
除非有非常充分的理由, 否则我们应该按标准库容器的风格来设计容器. 特别是, 通过容器实现为句柄并为其实现恰当的基本操作来令它是资源安全的.
标准库容器都知道自己的元素数目. 我们可以调用size()来获取.
for(size_t i = 0; i < c.size(); ++i) //size_t 是标准库size()返回类型的名字
c[i] = 0;
但是标准库算法并不是使用从0到size()的下标来遍历容器, 二是依赖于序列sequence的概念,一个序列是用一对迭代器iterator框定的.
for(auto p = c.begin(); p!= c.end(); ++p) *p = 0;
这里c.begin()是一个指向c的首元素是的迭代器. 而c.end()指向尾元素. 类似于指针,迭代器使用++操作移动到下一元素, 以及用*访问指向元素的值. 这种迭代器模型, 具有非常高的通用性和效率,用来将序列传��递给标准库算法.例如
sort(v.begin(),v.end())
另一种隐式使用元素数目的算法是范围for循环:
for(auto&x :v){
x = 0;
};
这段代码隐式的使用了c.begin()和c.end(),它大致等价于显式使用迭代器循环.
- 容器类模板提供了一些成员函数来实现容器的基本操作,其中包括:
- 往容器中增加元素
- 从容器中删除元素
- 获取容器中指定位置的元素
- 在容器中查找元素
- 获取容器首/尾元素的迭代器
这些成员函数往往具有通用性(大部分容器类模板都包含它们)。
如果容器的元素类型是一个类,则针对该类可能需要:
自定义拷贝构造函数和赋值操作符重载函数
对容器进行的一些操作中可能会创建新的元素(对象的拷贝构造)或进行元素间的赋值(对象赋值)。
重载小于操作符(<) 对容器进行的一些操作中可能要进行元素比较运算。
容器声明
都是 containerName<typeName,...> name 的形式,但模板参数(<> 内的参数)的个数、形式会根据具体容器而变。
本质原因:STL 就是「标准模板库」,所以容器都是模板类。
共有函数 =:有赋值运算符以及复制构造函数。
begin():返回指向开头元素的迭代器。
end():返回指向末尾的下一个元素的迭代器。end() 不指向某个元素,但��它是末尾元素的后继。
size():返回容器内的元素个数。
max_size():返回容器 理论上 能存储的最大元素个数。依容器类型和所存储变量的类型而变。
empty():返回容器是否为空。
swap():交换两个容器。
clear():清空容器。
==/!=/</>/<=/>=:按 字典序 比较两个容器的大小。(比较元素大小时 map 的每个元素相当于 set<pair<key, value> >,无序容器不支持 </>/<=/>=。)