概述
程序的生命周期是从一个高级 C 语言程序开始的,因为这种形式能够被人读懂。然而,为了在系统上运行 hello.c 程序,每条 C 语句都必须被其他程序转化为一系列的低级机器语言指令。然后这些指令按照一种称为可执行目标程序的格式打好包,并以二进制磁盘文件的形式存放起来。目标程序也称为可执行目标文件。
在 Unix 系统上,从源文件到目标文件的转化是由编译器驱动程序完成的∶
linux> gcc -o hello hello.c
在这里,GCC 编译器驱动程序读取源程序文件 hello.c,并把它翻译成一个可执行目标文件 hello。这个翻译过程可分为四个阶段完成。执行这四个阶段的程序(预处理器、编译器、汇编器和链接器)一起构成了编译系统(compilation system)。
I visualize the network of paths an implementation may choose as climbing a mountain. You start off at the bottom with the program as raw source text, literally just a string of characters. Each phase analyzes the program and transforms it to some higher-level representation where the semantics—what the author wants the computer to do—becomes more apparent. 我把一个语言实现可能选择的路径网络类比为爬山。你从最底层开始,程序是原始的源文本,实际上只是一串字符。每个阶段都会对程序进行分析,并将其转换为更高层次的表现形式,从而使语义(作者希望计算机做什么)变得更加明显。最终我们达到了峰顶。我们可以鸟瞰用户的程序,可以看到他们的代码含义是什么。我们开始从山的另�一边下山。我们将这个最高级的表示形式转化为连续的较低级别的形式,从而越来越接近我们所知道的如何让CPU真正执行的形式。
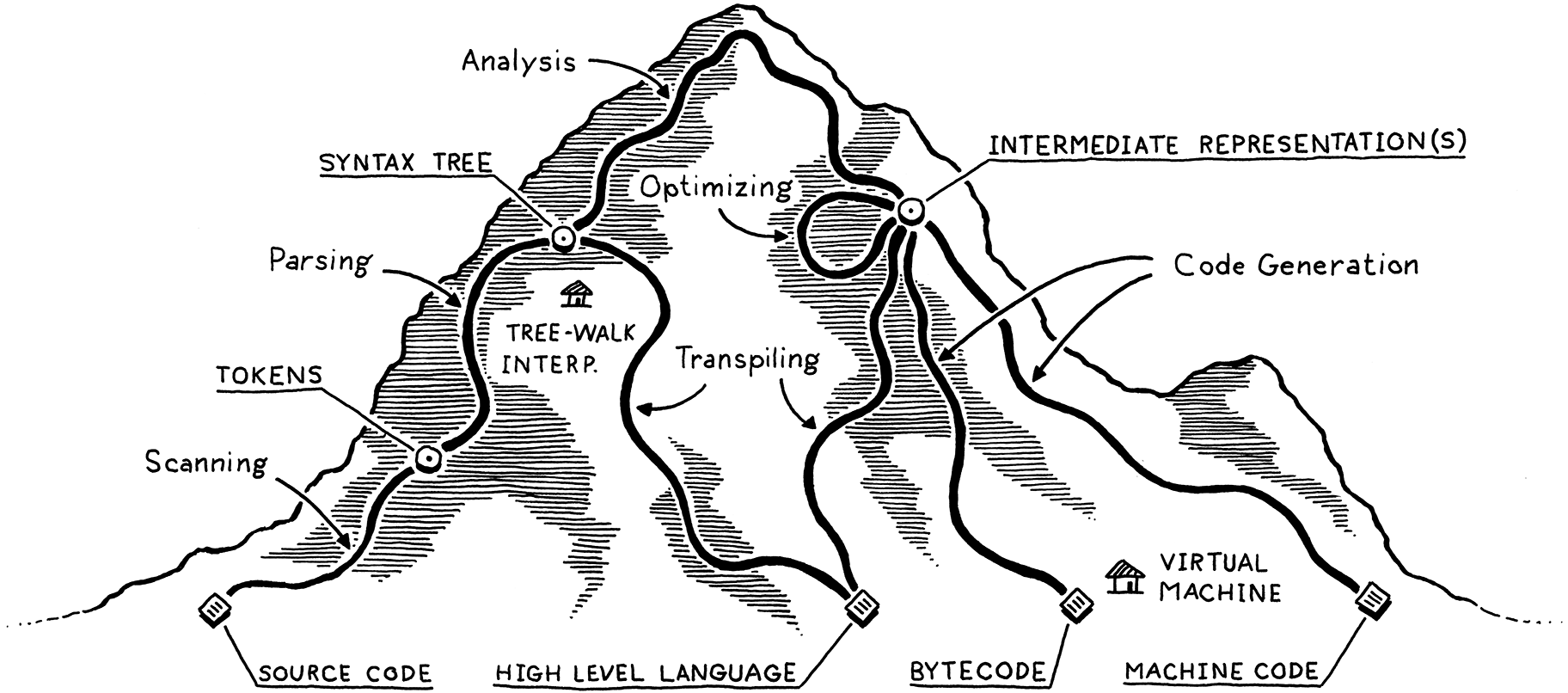
计算机不能直接理解高级语言,只能直接理解机器语言,所以必须要把高级语言翻译成机器语言,计算机才能执行高级语言编写的程序。
翻译的方式有两种,一个是编译,一个是解释。
编译型语言写的程序在执行之前,需要一个专门的编译过程,把程序编译成为机器语言的文件,比如 exe 文件,如果源程序不变以后要运行的话就不用重新翻译。
解释则不同,解释性语言的程序不需要编译,在运行程序的时候才翻译,翻译一句执行一句,不生成目标程序,这样解释性语言每执行一次就要翻译一次,效率比较低。
java文件->编译->.class文件,编译成.class字节码,.class需要jvm解释,然后解释执行。Java很特殊,Java程序需要编译但是没有直接编译成机器语言,即二进制语言,而是编译成字节码(.class)再用解释方式执行。java程序编译以后的class属于中间代码,并不是可执行程序exe,不是二进制文件,所以在执行的时候需要一个中介来解释中间代码,这就是所谓的java虚拟机(JVM),也叫JDK。
C语言编译过程分成四个步骤:
1, 由.c文件到.i文件,这个过程叫预处理
将#include包含的头文件直接拷贝到hell.c当中;将#define定义的宏进行替换,同时将代码中没用的注释部分删除等
2, 由.i文件到.s文件,这个过程叫编译
3, 由.s文件到.o文件,这个过程叫汇编
高级语言->汇编语言->机器语言
4, 由.o文件到可执行文件,这个过程叫链接
将翻译成的二进制与需要用到库绑定在一块
程序设计语言是向人以及计算机描述计算过程的记号.但是,在一个程序运行之前,它首先要被翻译成一种能够被计算机执行的形式.完成这项翻译工作的软件系统成为编译器compiler.
简单的说,编译器就是可以阅读某一种语言编写的程序的程序,并把该程序翻译成另一种语言的等价程序.编译器的重要任务之一:报告它在翻译过程中发现的源程序中的错误.如果目标程序是一个可执行的机器语言程序,那么他就可以被用户调用,处理输入并产生输出.
解释器是另一种常见的语言处理器.解释器的错误诊断效果比编译器好,因为它是逐个语句地执行源程序.除了编译器,创建一个可执行的目标程序还需要其他程序.一个源程序可能被分割成为多个模块,并存放于独立的文件中.把源程序聚合在一起的任务有时会由一个预处理器preprocessor的程序独立完成,预处理器还负责把宏的缩写形式转换为源语言语句.
预处理后的源程序作为输入传入编译器,输出一个汇编语言程序.
汇编语言程序经过汇编器assembler处理生成可重定位的机器代码.
大型程序经常被分为多个部分进行编译,因此,可重定位的机器代码有必要和其他可重定位的目标文件以及库文件连接在一起,形成真正在机器上运行的代码.一个文件(这里的文件指的是二进�制文件,和预处理器连接的文件不是一种文件)可以指向另一个文件中的位置.而链接器linker能够解决外部内存地址的问题,最后加载器loader把所有的可执行目标文件放到内存中执行.
经过预处理的源程序仍然是高级语言程序.
编译程序:将高级语言的源程序翻译成与之等价的低级语言的目标程序的这样一种程序
源程序运行过程:编译阶段+运行阶段或者编译阶段+汇编阶段+运行阶段
解释程序:以源程序作为输入,但不产生目标程序,解释一条执行一条
汇编程序:用于特定计算机上的汇编语言的翻译程序。有时编译器把汇编语言作为目标语言,然后再由汇编程序将它翻译成目标代码。
连接程序:将分别在不同的目标文件中编译或汇编的代码收集到一个可直接执行的文件中
装入程序:编译器、汇编程序或连接程序生成的代码还不能运行,装入程序处理所有的与指定的基地址有关的可重定位地址,并将修改后的指令和数据放在内存中适当的位置。
预处理程序:预处理程序是在真正的编译开始之前由编译器调用的独立程序。预处理程序可以删除注释、包含其它文件以及执行宏替代。
源程序+初始数据→解释程序→计算结果
源程序→编译程序→初始数据+目标程序+运行系统子程序→计算结果
编译过程
表格管理程序:登记源程序的各类信息和编译程序各阶段的进展情况,如符号表。
出错处理程序:发现并指出源程序中错误的性质和位置;自动校正错误
遍:对源程序��或源程序的中间结果从头至尾扫描一次,并作有关的加工处理,生成新的中间结果或目标程序的处理过程称为一遍。可以把一个阶段分为若干遍,也可以把多个阶段合为一遍,通常有一遍和多遍编译程序。
前端(front end):由与源语言有关但与目标机无关的部分组成。
后端(back end):包括与目标机有关的部分。而一般不依赖于源语言,只与中间代码有关的编译阶段。
编译器看作是一个黑盒子,将源程序映射为在语义上等价的目标程序。黑盒子内的映射部分由两个部分组成:前端(分析)和后端(综合)。 一般分为5个阶段:词法分析→语法分析→语义分析与中间代码产生→优化→目标代码生成
词法分析:按照语言的词法规则使用特定的工具将源程序转换成单词符号串 语法分析:按照语法规则使用上下文无关文法、确定的下推自动机将单词符号串转换为各类语法范畴 (层次结构分析) 语义分析与中间代码产生:按照语义规则使用属性文法将语法范畴进行初步翻译、产生中间代码(中间代码即独立于具体硬件的记号系统,四元式、三元式、逆波兰式等。) 优化:按照等价变换规则使用变换方法将中间代码变为更高效的中间代码 目标代码生成:将中间代码转换成依赖于机器的目标代码
main:
subq $8, %rsp
movl $.LC0, %edi
call puts
movl $0, %eax
addq $8, %rsp
ret